
It’s amazing how Andrej Karpathy managed to summarize where everything is going so clearly. We need more voices like his in this field, people who can make the future of software feel obvious once you hear it.
Software is undergoing fundamental changes, a rare occurrence in its 70-year history, having only shifted significantly twice recently.
This rapid evolution presents many opportunities and challenges for new professionals.If you’re building anything in tech, this talk changes how you’ll think about code, creativity, and computers.
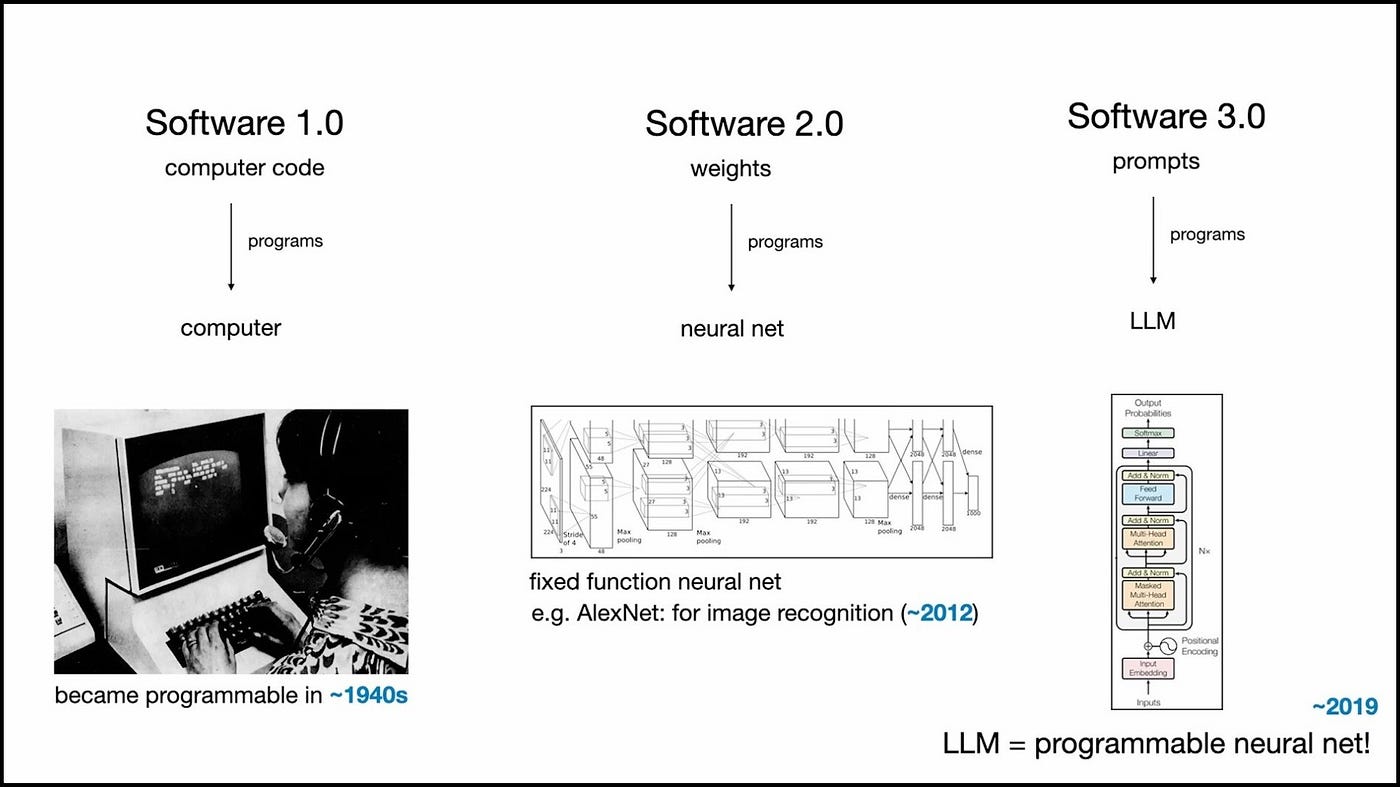
The three software paradigms.
Software 1.0: Traditional Code
Software 2.0: Neural Networks
Software 3.0: LLM Programming
Software, at its core, has always been about giving instructions to machines. For most of its 70-year history, that meant writing code lines of logic and syntax that told computers exactly what to do. That was Software 1.0 the world of GitHub, where every function, loop, and variable is hand-crafted by a developer.
Then came the second era. Instead of explicitly writing rules, we began training machines to learn them from data. In Software 2.0, the real code isn’t what you see on GitHub, it’s the neural network weights hidden inside models. You don’t program them directly; you shape them by tuning datasets and running optimizers.
The shift from Software 1.0 to 2.0 wasn’t just theoretical it played out in the real world, inside systems that had to make life-and-death decisions on the road.Back when Karpathy was working on Tesla’s Autopilot, the codebase was filled with thousands of lines of carefully written C++ traditional,(Software 1.0) rule-based logic telling the car how to see, decide, and steer. Every new capability meant more code, more conditions, and more complexity.
But something fascinating started happening. Neural networks(Software 2**.0)**) began taking over.At first, they handled small, well-defined tasks like recognizing lanes or traffic lights. Then they started doing more fusing data from multiple cameras, tracking motion over time, and even reasoning about the environment.
Each time the neural network got smarter, a chunk of old C++ code became unnecessary and was deleted. The “manual” logic that engineers had painstakingly written was replaced by learned behavior that emerged from data.

Software 2.0 stack literally ate through the Software 1.0 stack
Over time, the Software 2.0 stack literally ate through the Software 1.0 stack.
The more they improved the models, the less human code was left. What used to be thousands of lines of instructions turned into a set of weights learned by a neural net, a model that couldn’t explain how it made decisions, but could often make them better than a handcrafted algorithm ever could.
It was a striking realization: software wasn’t being written anymore -it was evolving.
A Huge Amount of Software Will Be Rewritten
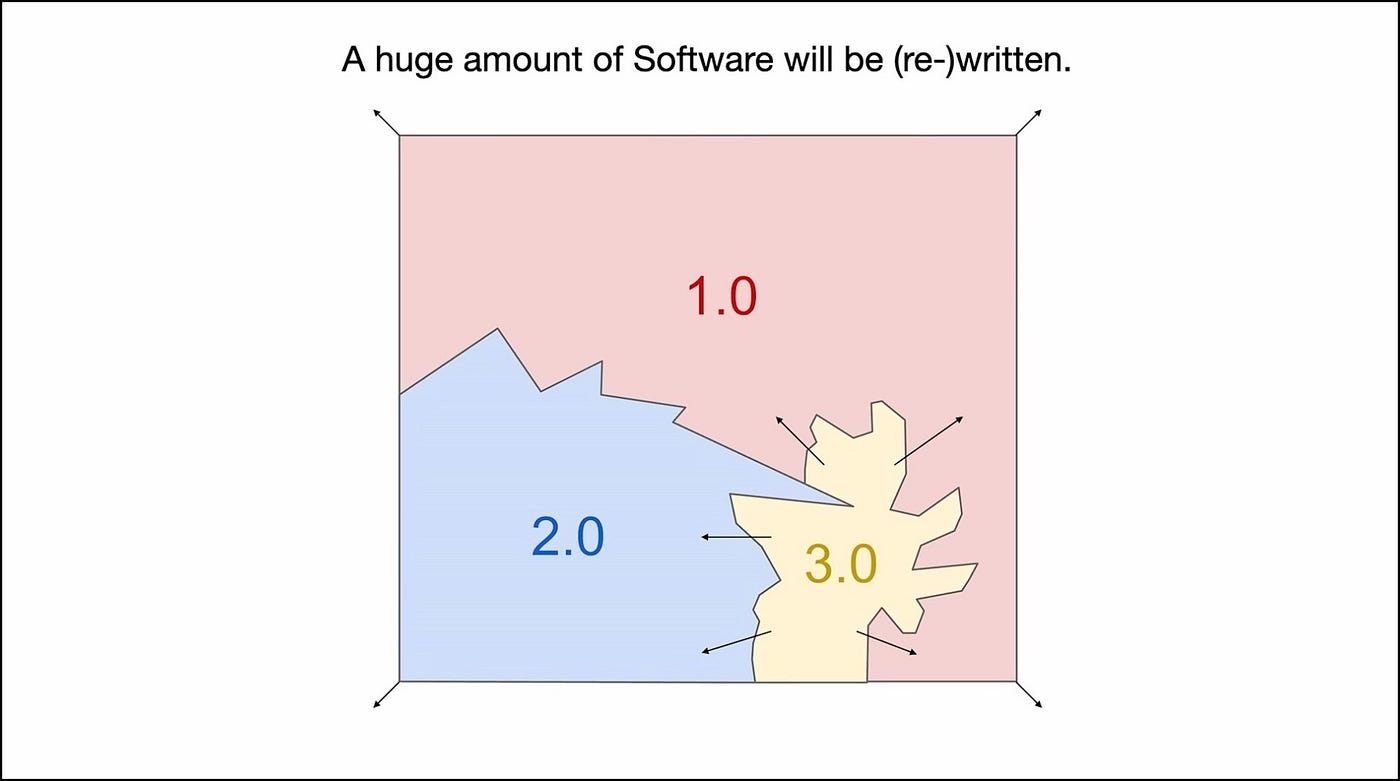
What happened at Tesla was just the beginning. The same story is repeating itself across the entire software world a new kind of software is eating through the stack once again.
We’ve moved from Software 1.0 (explicitly written code) to Software 2.0 (learned neural networks), and now we’re stepping into Software 3.0, where natural language itself becomes the programming interface. Each paradigm brings its own strengths, precision and control in 1.0, adaptability and scale in 2.0, and creativity and accessibility in 3.0.
Karpathy’s viral tweet
For anyone entering the field, fluency across these paradigms is becoming essential. The modern engineer won’t just ask “What language should I code this in?” but rather “Which paradigm should I use?”
The boundaries are blurring, and the ability to fluidly transition between 1.0, 2.0, and 3.0 will define the next generation of developers.1
LLMs Are Kind of Like a New Operating System.

When the Grid Goes Down, The World Gets Dumber
Andrew Ng once said something that stuck with Karpathy: “AI is the new electricity.” Years later, that metaphor feels less like poetry and more like infrastructure reality.
Think about what happened just days before this talk. Multiple LLMs went down simultaneously. And people? They were stuck. Unable to work. Not because their computers crashed, but because their intelligence supply was cut off.
Karpathy calls it an “intelligence brownout” like when voltage drops in the power grid and your lights flicker. Except this time, it’s not your lights dimming. The planet itself gets a little bit dumber.
That’s how dependent we’ve already become.

The Utility Model: Building the Intelligence Grid
LLMs really do behave like utilities. The economics alone tell the story.
OpenAI, Google’s Gemini, Anthropic these labs spend enormous capital upfront to train their models. That’s the capex, the “building out the grid” phase. Then comes the opex: serving that intelligence over APIs, metered by the million tokens, always-on, globally distributed.
And what do we demand from them? The same things we demand from any utility:
- Low latency (because waiting for intelligence feels broken)
- High uptime (because downtime means we can’t work)
- Consistent quality (because unreliable outputs aren’t just annoying, they’re unusable)
We even have the equivalent of a transfer switch. In electricity, you can switch between grid power, solar, battery, or generator. In LLMs, we have services like OpenRouter that let you toggle between GPT, Claude, Gemini-whatever model fits the moment.
And here’s the kicker: unlike physical infrastructure, these providers don’t compete for space. You can have six different “electricity providers” running simultaneously because they’re software. They coexist. You switch between them with a dropdown menu.

But LLMs Aren’t Just Utilities -They’re Also Fabs
The utility metaphor works, but it’s incomplete.
LLMs also share traits with semiconductor fabrication plants (fabs). The capex isn’t just large, it’s massive. Training frontier models isn’t like building a power station. It’s closer to constructing a cutting-edge chip manufacturing facility and billions of dollars, deeply specialized infrastructure, and proprietary know-how.
The technology tree is growing fast. Research secrets, architectural innovations, training techniques they’re centralizing inside LLM labs. There’s a kind of “deep tech moat” forming, similar to how TSMC or Intel guard their process nodes.
Some rough analogies emerge:
- A 4-nanometer process node might map to a training cluster with certain max FLOPS
- The fabless model (using NVIDIA GPUs without owning hardware) mirrors companies that train models but don’t build chips
- The Intel model (owning your fab) is like Google training on TPUs vertical integration all the way down
But software is different. It’s malleable. Less defensible. You can’t just airgap an algorithm the way you can a physical fab. So the analogy stretches thin.
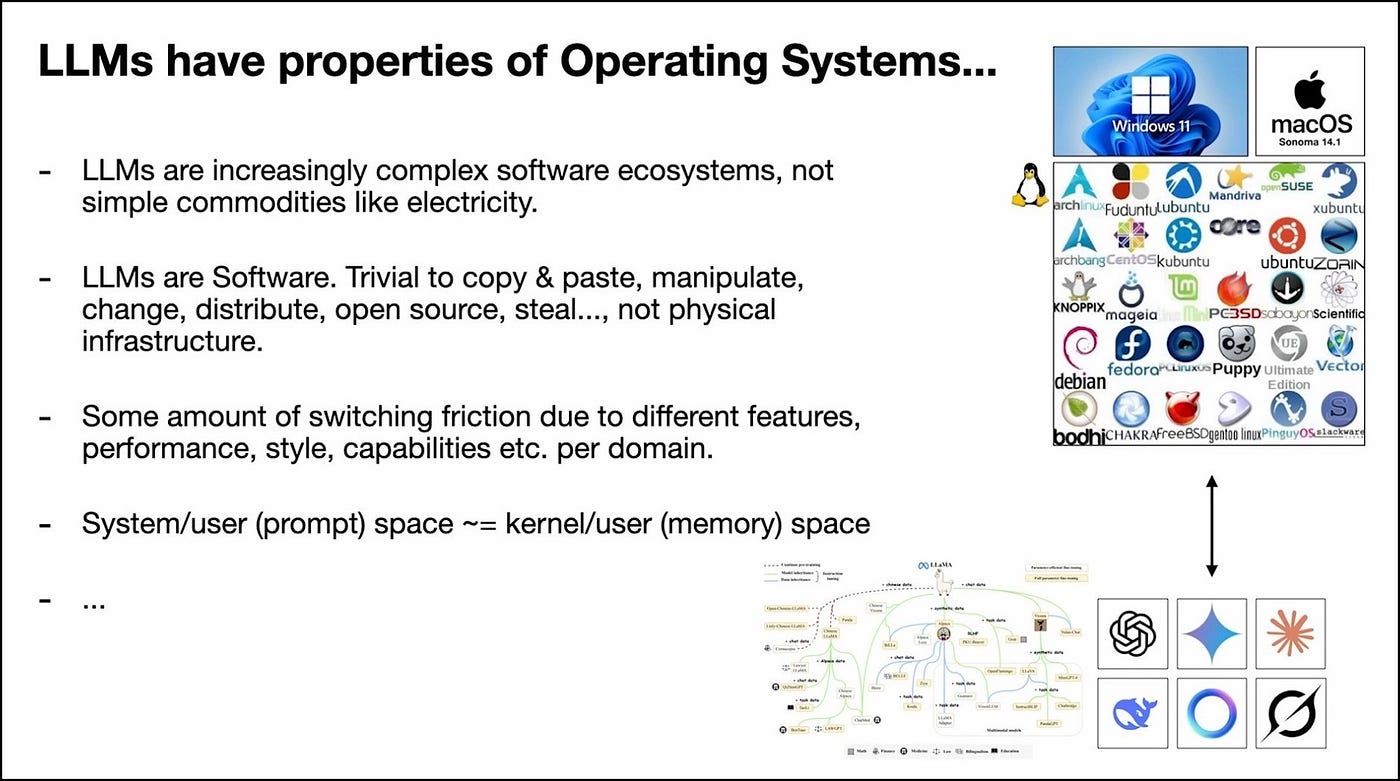
The Real Analogy: LLMs Are Operating Systems
Here’s where it clicks.
LLMs aren’t just electricity. They’re not water from a tap. They’re complex software ecosystems and the ecosystem is shaping up eerily similar to how operating systems evolved.
Get Sourabh Ligade’s stories in your inbox
Join Medium for free to get updates from this writer.
Subscribe
Subscribe
You have:
- A few closed-source providers (like Windows or macOS)-think GPT, Claude, Gemini
- An open-source alternative (like Linux)-currently taking shape around Meta’s Llama ecosystem
It’s still early. These are “just” LLMs right now. But they’re rapidly becoming more …tool use, multimodality, agentic behavior. The complexity is compounding.
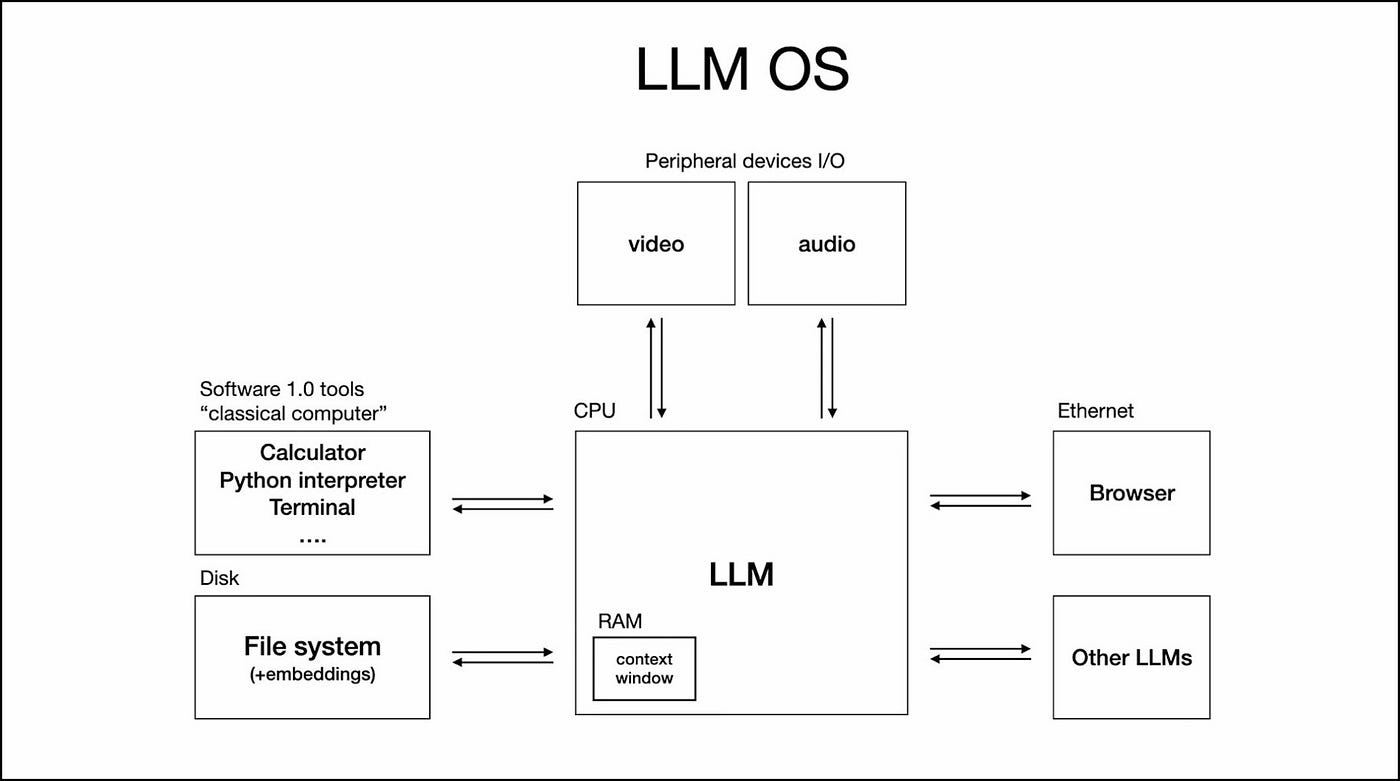
Karpathy sketched it out like this:
The LLM is the new CPU.The context window is the new RAM.And the LLM orchestrates memory and compute for problem-solving.
Look at the structure:
- The model sits at the core, processing information
- The context window holds working memory
- Tools extend functionality (like system calls or drivers)
- Multimodal inputs flow in (vision, audio, etc.)
It’s an operating system. Just… cognitive.
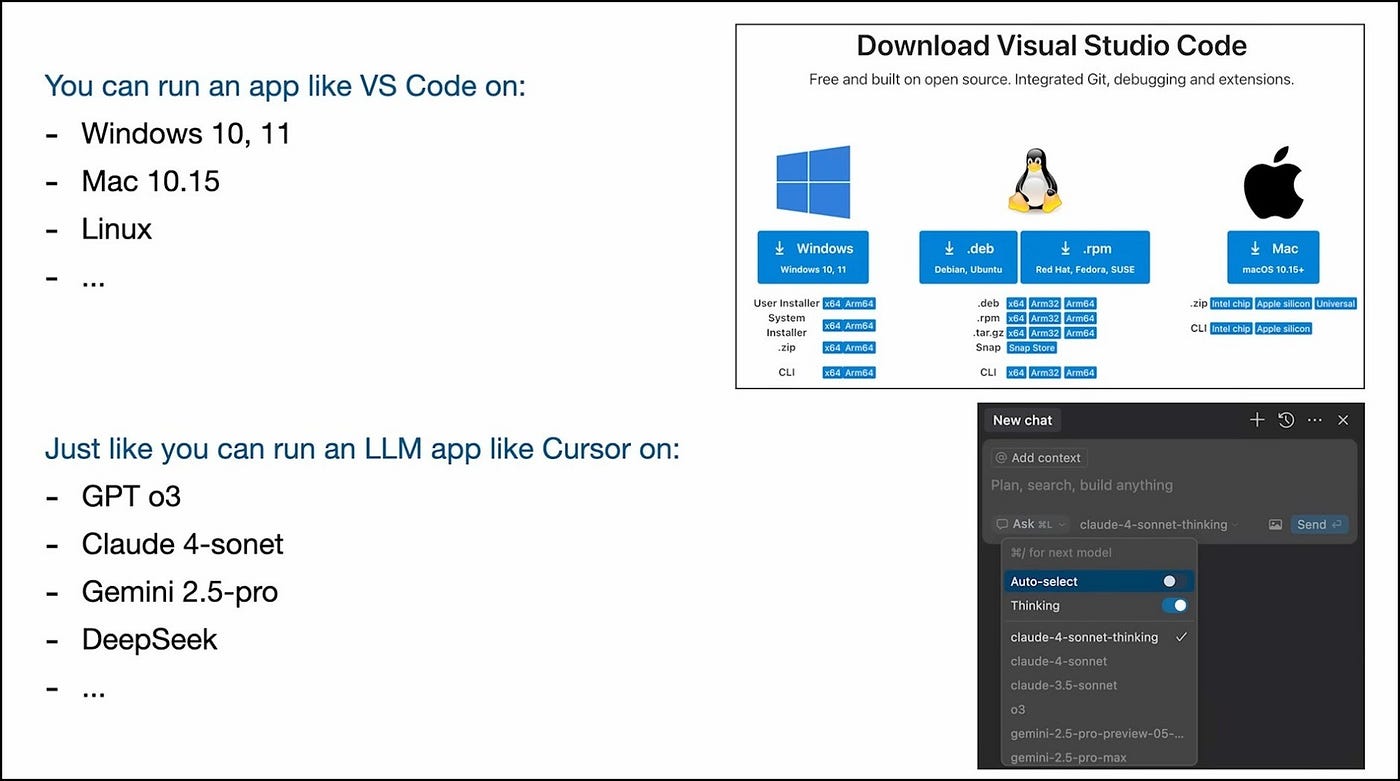
Apps Run on Operating Systems. So Do LLM Apps.
Take VS Code. You download it once, and it runs on Windows, Linux, or macOS. Same app, different OS.
Now take Cursor (the AI-powered code editor). You can run it on GPT, Claude, or Gemini. It’s just a dropdown. Same app logic, different “cognitive OS.”
The pattern is the same. The abstraction layer is forming. And just like developers once had to choose between targeting Windows vs. Mac vs. Linux, they’ll soon be designing for GPT vs. Claude vs. Llama each with its own quirks, strengths, and ecosystems.

Chapter 3: We’re Living in the 1960s (Again)
The Personal Computing Revolution Hasn’t Happened Yet
Here’s a strange realization: we’re in the 1960s again.
Not culturally. Technologically.
Back then, computers were massive, expensive, and centralized. You didn’t own a computer -you got time on one. Everyone shared. The operating system lived in the cloud (well, in some building with raised floors and humming mainframes), and you accessed it through a thin client over a network.
Sound familiar?
That’s exactly where we are with LLMs. The compute is still too expensive. Running a frontier model locally? Economically absurd for most use cases. So the LLMs stay centralized in the cloud, and we’re all just… dimensions in a batch. Time-sharing intelligence.
The personal computing revolution is the moment when everyone gets their own cognitive processor sitting on their desk ,hasn’t happened yet.
But Some People Are Trying
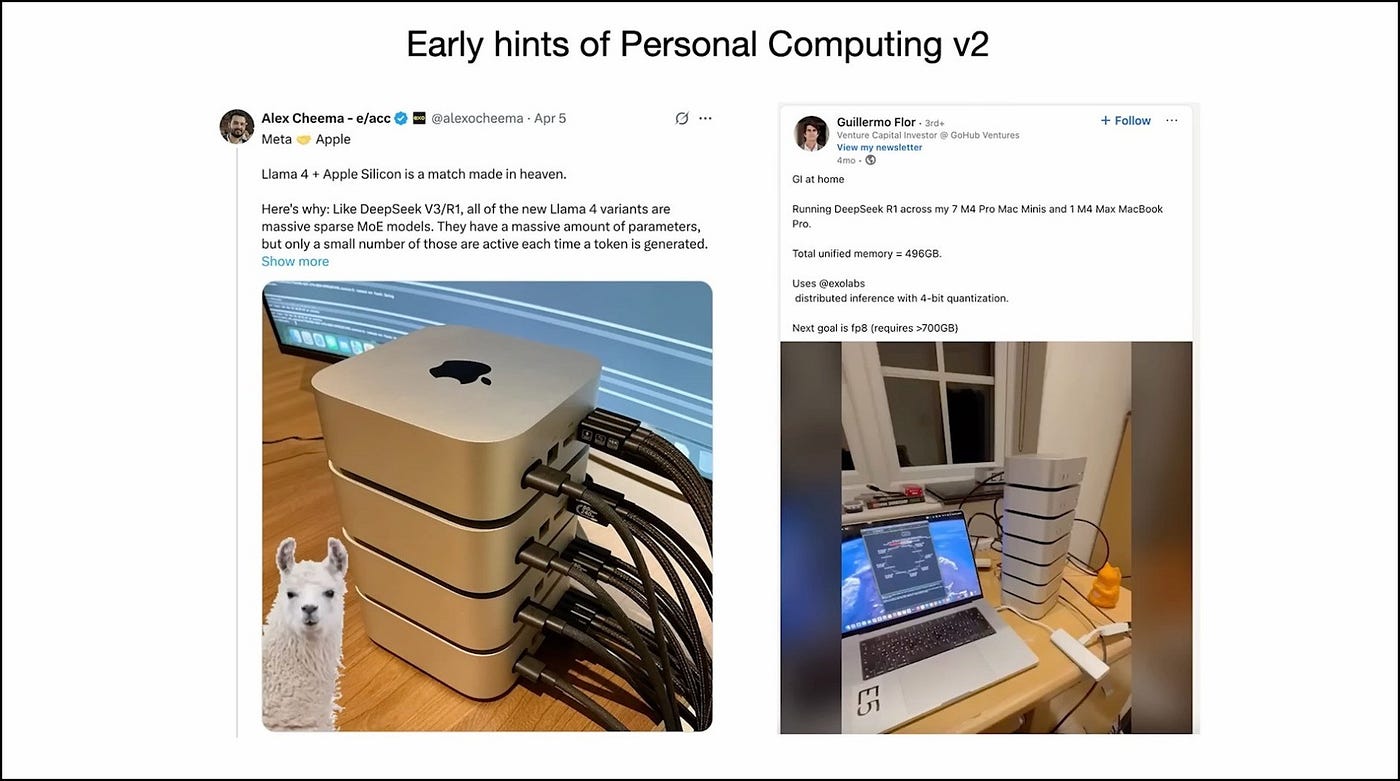
There are early hints. Mac Minis, for instance, can run some smaller LLMs surprisingly well. Why? Because batch-one inference (running one query at a time) is memory-bound, not compute-bound. You don’t need a massive GPU farm for personal use -you need enough RAM and decent bandwidth.
These are the first whispers of local AI. But we’re not there yet. Not really.
What does personal LLM computing even look like? How does it work? What should it be?
Nobody knows yet. Maybe you get to invent it.
We’re Still Talking to the Terminal
When Karpathy talks to ChatGPT, he feels like he’s using a command-line interface. Text in, text out. Direct access to the OS. No frills.
And he’s right -we’re basically in the terminal era of LLMs.
The GUI hasn’t been invented yet. Not in a general way. Sure, ChatGPT has text bubbles. Some apps have custom interfaces. But there’s no unified visual language for interacting with intelligence across all tasks. No equivalent to windows, icons, menus, pointers.
The LLM GUI is still waiting to be discovered.
But Here’s Where It Gets Weird

LLMs break a pattern that’s been consistent across almost every transformative technology in history.
Normally, tech diffuses like this:
Government/Military → Corporations → Consumers
Electricity? Military and industrial first.
Cryptography? Intelligence agencies.
Early computing? Ballistics and weapons systems.
Internet? ARPANET -funded by defense.
GPS? Military navigation before it was in your phone.
New, expensive, powerful technologies are adopted by institutions first because they can afford the risk and cost. Then, eventually, they trickle down.
LLMs flipped this completely.
Consumers got here first. The first mass use cases weren’t military strategy or corporate optimization. They were:
- “How do I boil an egg?”
- “Help me write an email.”
- “Explain this concept like I’m five.”
Karpathy himself admits — he’s got this magical new computer, and half the time, it’s teaching him to cook.
Meanwhile, corporations and governments are lagging behind. They’re still figuring out procurement, compliance, risk assessment. By the time they deploy LLMs at scale, the consumer space will have already reshaped how these models are used.
Why This Matters
This reversal isn’t just trivia. It tells you where the first real applications will emerge.
The frontier isn’t going to be some hyper-specialized enterprise tool locked behind procurement hell. It’s going to be apps that solve everyday problems, creatively and immediately — tools that individuals adopt before institutions even notice.
The people defining how LLMs get used aren’t in boardrooms. They’re in Discord servers, GitHub repos, and chat threads at 2 AM.
What Comes Next in Part 2
We’ve traced software’s evolution from explicit code to learned behaviors to natural language interfaces. We’ve seen LLMs forming a new operating system centralized, utility-like, still waiting for its personal computing moment.
But the real questions are just starting: What does it mean when these systems display jagged intelligence superhuman at some tasks, basic failures at others? How do you build on entities with anterograde amnesia, where context is just working memory?
The first self-driving demo was 2013. Twelve years later, we’re still working on it. When people say “2025 is the year of agents,” Karpathy gets concerned. This is the decade of agents and we need to move carefully.
Meanwhile, the vibe coding revolution is collapsing barriers. Everyone who speaks natural language is suddenly a programmer. The code is the easy part now.
We’re still in the terminal. The GUI hasn’t been invented. Text is hard to verify at scale. **AIs generate. Humans verify.**The bottleneck is making verification fast enough.
Stay tuned for part 2